

The AI technology has seen a tremendous breakthrough, and there are already many practical tools available online that utilize the ChatGPT or OpenAI technology. This article will guide you on how to apply for a ChatGPT API key and how to use ChatGPT in GitHub and Python. Keep reading to learn more.
🙋♂️ How to use ChatGPT ? Latest Information
🔖 upgrade、app、api、plus、alternative、login、download、sign up、website、stock
How to get ChatGPT API Key
As long as you have an account with ChatGPT, you can apply for your own API key, and the process is quite simple. Just follow the steps below :
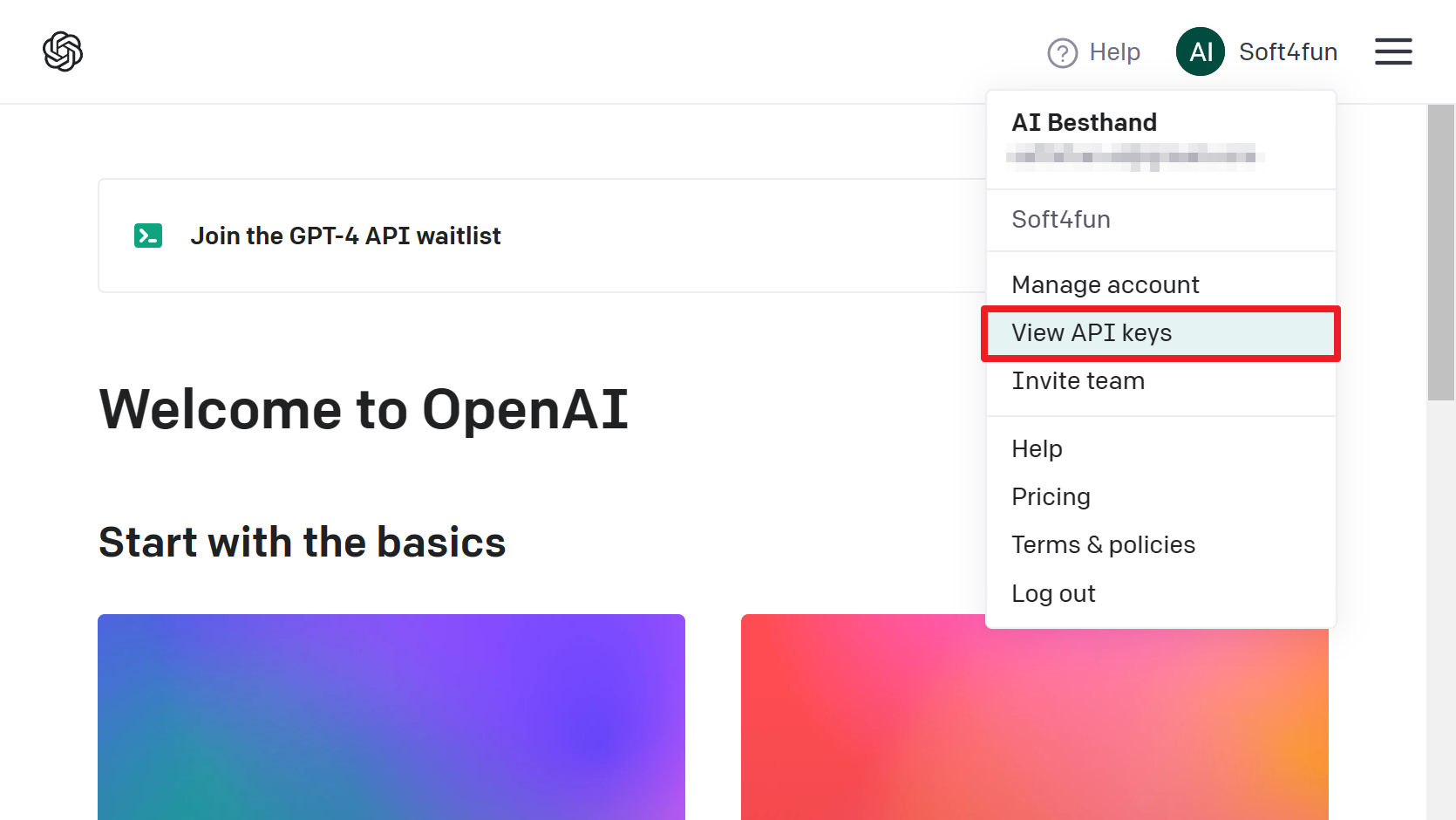
step1 : Go to the OpenAI API Key application page
Click on this link or select “View API Keys” from the menu in the upper right corner of the OpenAI website to access the page.
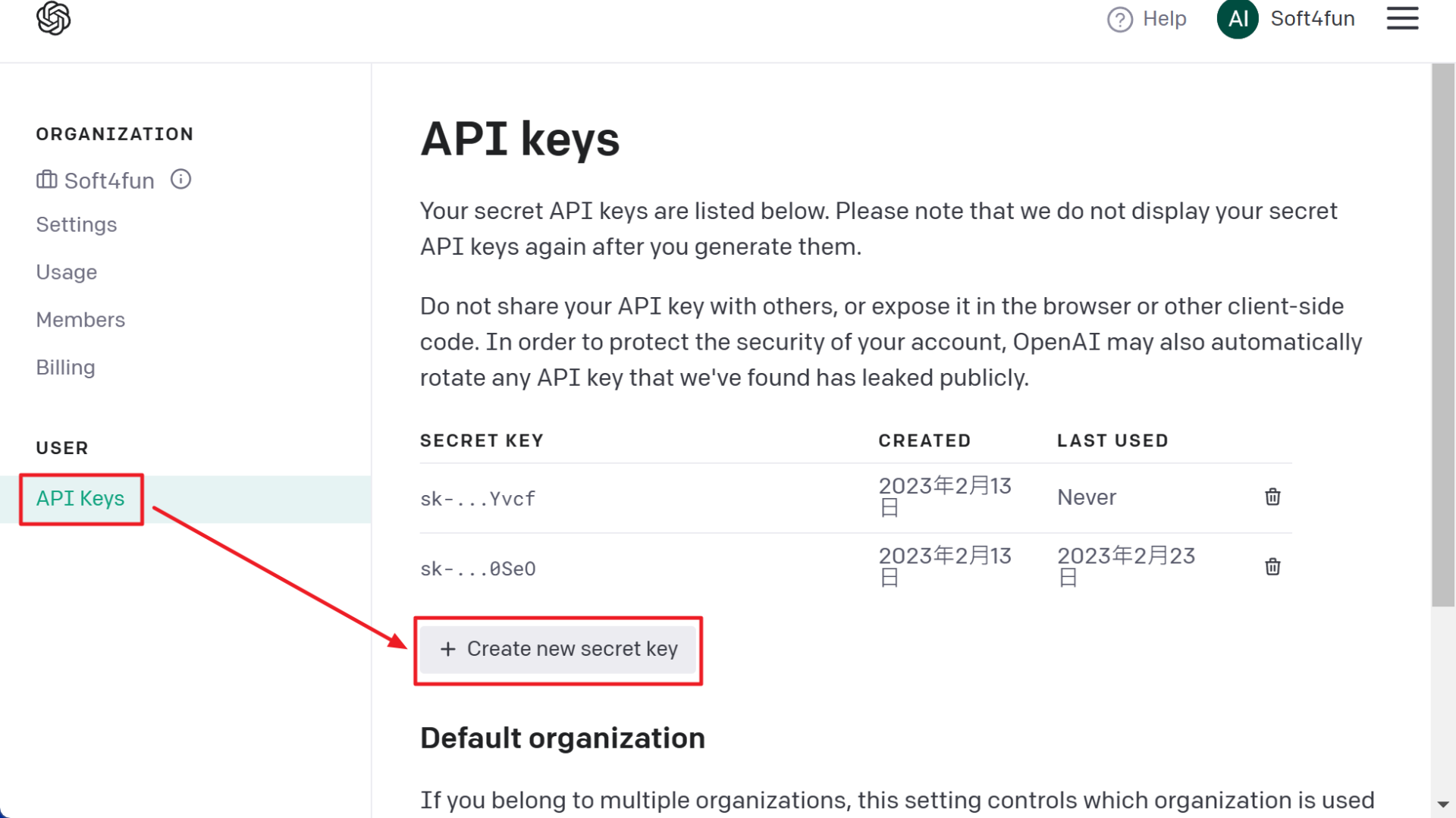
step2 : Create your own API key
Click on the “+ Create new secret key” button on the page.
step3 : Copy and save the API key in a secure place
The system will generate a string of alphanumeric characters, which is your unique API key. Copy it immediately and store it in a secure location. Note: Once you click OK or leave this page, you won’t be able to see the key again.

Using HTTP POST to call the OpenAI API
On the API page, log in or switch to the Overview page. You will see the provided functionalities categorized. For chat-based functionalities like ChatGPT, it falls under Text Completion. The basic concept is that you provide a prompt, and the API responds with a continuation of that prompt.
If you check the API reference documentation, you will find that Text Completion needs to be accessed using the HTTP POST method. You can test it with the following curl command:
curl https://api.openai.com/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer your API key' \
-d '{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
}'Key Parameter of ChatGPT API
The most important thing is to include your API key in the headers. In the message body, the relevant parameters must be passed in JSON format. The meanings of the key parameters are as follows:
| Parameter Name | Description |
| model | The pre-trained model to use from OpenAI. While there are several options, “text-davinci-003” is recommended for chat-based applications. This parameter is required and must be provided. |
| prompt | The input prompt to be given to OpenAI. In the case of chat, it represents what you want to say. |
| max_tokens | The maximum number of tokens in the generated response. The total number of tokens, including both the prompt and the response, must not exceed the limit of the chosen model. For “text-davinci-003”, the total should not exceed 4097 tokens. Here, a token does not necessarily correspond to a complete word; a single word may be split into multiple tokens. You can use official tools to understand the tokenization results. |
| temperature | The level of randomness, ranging from 0 to 1. The text completion generates text by selecting the next token based on the current content. A higher value for this parameter considers tokens with lower prediction probabilities, resulting in more varied responses. Setting it to 0 makes it more deterministic, always selecting the token with the highest prediction probability, which means the same prompt will result in the same response. |
| n | The number of responses to generate. |
| stop | A string array that specifies the stopping conditions. If the generated text contains any of the specified strings, the response generation will stop. Up to 4 strings can be set. |
| presence_penalty | A value between -2.0 and 2.0. A higher value penalizes the repeated use of tokens, encouraging the generation of new tokens while constructing sentences. |
| frequency_penalty | A value between -2.0 and 2.0. A higher value penalizes tokens with high frequency, avoiding repetition. |
| suffix | The AI will add appropriate text between the prompt and the suffix to ensure logical coherence. |
| best_of | The AI will generate “best_of” responses and return the one with the highest score. |
Create a variable to store the API key
Next, we will follow the guidelines mentioned above and use Python to test it. First, create a variable to store the API key:
>>> api_key = 'your API key'Since we will be using HTTP POST, I will use the requests module. If you haven’t installed it yet, you can install it by using the command “pip install requests”.
>>> import requestsUse the API
Next, you can use the API
>>> response = requests.post(
... 'https://api.openai.com/v1/completions',
... headers = {
... 'Content-Type': 'application/json',
... 'Authorization': f'Bearer {api_key}'
... },
... json = {
... 'model': 'text-davinci-003',
... 'prompt': 'hello',
... 'temperature': 0.4,
... 'max_tokens': 300
... }
... )Check the HTTP status code
In the headers, we pass in the API key that we set earlier as an f-string. After executing it, we can check the HTTP status code.
>>> response.status_code
200A status code of 200 indicates success. Next, let’s examine the returned content.
>>> print(response.text)
{"id":"cmpl-6X3PDJv9VwTsoVGSonytEFYWnjAip","object":"text_completion","created":1673335935,"model":"text-davinci-003","choices":[{"text":"\n\nhello!","index":0,"logprobs":null,"finish_reason":"stop"}],"usage":{"prompt_tokens":4,"completion_tokens":9,"total_tokens":13}}It is clearly a JSON-formatted data. Here is the reformatted content:
{
"id": "cmpl-6X3PDJv9VwTsoVGSonytEFYWnjAip",
"object": "text_completion",
"created": 1673335935,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nhello!",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 4,
"completion_tokens": 9,
"total_tokens": 13
}
}Among them, “choices” represents the generated response sentences, and “usage” represents the number of individual tokens used for the prompt and response. This is also used to calculate your account usage. Since we haven’t set any other parameters, it will only return a single sentence. You can extract it using the following method:
>>> json = response.json()
>>> print(json['choices'][0]['text'])
hello!If there are parameter errors
f there is an error in the parameters, for example, if “max_tokens” is misspelled as “max_token” without the ‘s’
>>> response = requests.post(
... 'https://api.openai.com/v1/completions',
... headers = {
... 'Content-Type': 'application/json',
... 'Authorization': f'Bearer {api_key}'
... },
... json = {
... 'model': 'text-davinci-003',
... 'prompt': 'hi',
... 'temperature': 0,
... 'max_token': 300
... }
... )the HTTP status code will return 400
>>> response.status_code
400The returned content will only contain the “error” element, indicating the reason for the error.
>>> print(response.text)
{
"error": {
"message": "Unrecognized request argument supplied: max_token",
"type": "invalid_request_error",
"param": null,
"code": null
}
}Specify the max_tokens parameter that limits the number of tokens
The “finish_reason” in each element of the “choices” represents the reason for termination. “STOP” indicates a normal termination, while “length” indicates that the response exceeded the word count specified by “max_tokens”. For example, if we set “max_tokens” to 30 and ask a more complex question:
>>> response = requests.post(
... 'https://api.openai.com/v1/completions',
... headers = {
... 'Content-Type': 'application/json',
... 'Authorization': f'Bearer {api_key}'
... },
... json = {
... 'model': 'text-davinci-003',
... 'prompt': 'have you ever watched slam dunk?',
... 'temperature': 0.4,
... 'max_tokens': 30
... }
... )The execution result is as follows. You can see that the response was not completed yet, but it ended because it exceeded the limit:
>>> json = response.json()
>>> print(json['choices'][0]['text'])
Yes, I watched Slam Dunk
>>> print(json['choices'][0]['finish_reason'])
lengthSpecifying the “n” parameter for the number of response sentences
If you set the “n” parameter, it will return the specified number of sentences. For example:
>>> response = requests.post(
... 'https://api.openai.com/v1/completions',
... headers = {
... 'Content-Type': 'application/json',
... 'Authorization': f'Bearer {api_key}'
... },
... json = {
... 'model': 'text-davinci-003',
... 'prompt': 'hi',
... 'temperature': 0.4,
... 'max_tokens': 300,
... 'n': 2
... }
... )
>>> json = response.json()
>>> for item in json['choices']:
... print(f"{item['index']}{item['text']}")
0,Hello! Nice to meet you! Can I help you with anything?
1,Hello! Nice to meet you!You can see that because the “n” parameter is set to 2, it returns 2 sentences.
Specifying the “stop” parameter for ending sentences:
You can also set the “stop” parameter to specify certain text sequences (up to 4) that, when encountered, will stop the response to avoid inappropriate statements from the AI. For example:
>>> response = requests.post(
... 'https://api.openai.com/v1/completions',
... headers = {
... 'Content-Type': 'application/json',
... 'Authorization': f'Bearer {api_key}'
... },
... json = {
... 'model': 'text-davinci-003',
... 'prompt': 'hi',
... 'temperature': 0.4,
... 'max_tokens': 300,
... 'stop':['welcome', 'good']
... }
... )
>>> json = response.json()
>>> print(json['choices'][0]['text'])
,你You can see that the response above is incomplete at the end. It is assumed that it was supposed to reply with “hello” , but it stopped at the occurrence of the word “good”
You may also notice that, since text completion is not actually a conversation but rather completing text for you, when you only type “hi”, it will first add a comma and then continue with the rest of the text. In other words, it was originally intending to complete it as “hi,hello” .
Inserting text using the “suffix” parameter:
Inserting text using the “suffix” parameter:
Text completion can also insert text between the two paragraphs you provide. The first paragraph is the “prompt,” and the “suffix” parameter represents the second paragraph. For example:
>>> response = requests.post(
... 'https://api.openai.com/v1/completions',
... headers = {
... 'Content-Type': 'application/json',
... 'Authorization': f'Bearer {api_key}'
... },
... json = {
... 'model': 'text-davinci-003',
... 'prompt': 'i want to learn',
... 'suffix': 'change jobs',
... 'temperature': 0.7,
... 'max_tokens': 3000
... }
... )The result returned by the AI is as follows:
>>> print(response.json()['choices'][0]['text'])
I want to learn human resources management, because I want to improve my workplace skills to help me better manage my team, and better communicate with colleagues, and more importantly, to improve my management ability, so that I can have more opportunities for promotion or higher
>By combining the prompt and suffix provided to the AI, the complete content becomes:
I want to learn human resource management because I want to enhance my workplace skills, to assist me in better managing my team and communicating with colleagues. Moreover, it is essential to improve my management abilities to increase opportunities for promotion or career transition.

Using the openai module
The aforementioned process using requests.post can be a bit cumbersome. OpenAI provides the openai module, which can be installed directly using pip.
Please note that at the time of writing this article, the openai version is 0.26.0. However, if you’re using Python 3.10 on Windows, the installation may encounter errors. It is recommended to downgrade the version to 0.25.0 for a successful installation.
On the OpenAI API webpage, a Playground is provided for users to experience the functionalities, and you can also open the “View code” section to inspect the corresponding code, which utilizes the openai module. In the following example, we demonstrate the use of the openai module to connect to the Text Completion API. First, you need to import the module and set up your API key:
>>> import openai
>>> openai.api_key = f'{api_key}'Replace {api_key} with your own key. Then, you can utilize the existing methods to perform an HTTP POST request, eliminating the need for manually setting headers and dealing with JSON formatting details:
>>> response = openai.Completion.create(
... engine = 'text-davinci-003',
... prompt = 'hi',
... temperature = 0.7,
... max_tokens = 300
... )
>>>The result of this method has the characteristics of a Python dictionary, allowing you to access the content directly as a dictionary:
>>> response['choices'][0]['text']
',大家好!\n\nhi, everyone!'*大家好 is chinese,means hi everyone in english.
Calculating token count and cost
f you want to know how many tokens are in your prompt, OpenAI does not provide an API for that purpose. However, you can use the transformers package instead. Please install the package using pip install transformers to generate a GPT2TokenizerFast, which will tokenize your text:
>>> from transformers import GPT2TokenizerFast
>>> tokenizer = GPT2TokenizerFast.from_pretrained('gpt2')Here, we use the pre-trained model gpt2. The following code retrieves the parsed result of the specified sentence:
>>> t = tokenizer("hamburger")
>>> print(t)
{'input_ids': [2763, 6236, 1362], 'attention_mask': [1, 1, 1]}
>>>With the list of token IDs, you can determine the token count by using the length of the list. You can also directly return the count:
>>> t = tokenizer("hamburger", return_attention_mask=False, retu
... rn_length=True)
>>> t
{'input_ids': [2763, 6236, 1362], 'length': [3]}Here, we also specify not to return the attention mask to reduce the data size, although the token IDs cannot be omitted.
Making the conversation more conversational
When using Text Completion, the OpenAI API does not respond like ChatGPT, which considers the conversation history for answering. Each question and answer is treated as an independent event. For example, with the following sequential Q&A:
import openai
# Set the API key
openai.api_key = "your API key"
while True:
# Read a message from the user
message = input("You: ")
# Use GPT-3 to generate a response
response = openai.Completion.create(
engine="text-davinci-003",
prompt = message,
max_tokens=2048,
temperature=0.9,
)
print("Bot: ", response.choices[0].text)You’ll notice that there is no coherence between the consecutive questions and answers, like this:
# py chat.py
You: Which area is most affected by ocean pollution?
Bot:
答:Atlantic region
You: What about Taiwan?
Bot:
Taiwan is an island country in Asia, located in the southeast of China. It is a country with diverse cultures and rapid economic growth. Taiwan is one of the fastest growing economies in the world, with advanced technology and a free market, and a high level of healthy economic and social development. Taiwan has a perfect combination of Eastern culture and Western modernization, and it is also a good place with strong sports, education and cultural atmosphere.
You:If you want to create continuity in the conversation, you can include the previous dialogue along with the current prompt. For example:
import openai
# Set the API key
openai.api_key = "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"
prev_prompt = ''
prev_ans = ''
while True:
# Read a message from the user
message = input("You: ")
# Use GPT-3 to generate a response
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prev_prompt + "\n"+ prev_ans + "\n" + message,
max_tokens=2048,
temperature=0.9,
)
# Print GPT-3's response
print("Bot: ", response.choices[0].text)
prev_prompt = message
prev_ans = response.choices[0].textIn the above example, we simply include the previous question and answer, and the conversation becomes more related:
# py chat.py
You: Which area is most affected by ocean pollution?
Bot:
Ocean pollution has the greatest impact on marine life in all oceans, with those in Europe, the North and South American oceans most affected. Especially since 1990, there has been an increase in pollution mainly caused by illegal dumping of plastics in the Northeast Pacific Ocean and the Caribbean Ocean, and fishery residues in the Mediterranean, Atlantic and Arctic Oceans have caused great pollution to marine life plants and animals, especially fish.
You: What about Taiwan?
Bot:
Taiwan is located in the Western Pacific Ocean and the South China Sea, and is greatly affected by pollution from areas adjacent to Asia and Oceania, such as estuary pollution, oil pollution, and drug residues. In addition, Taiwan is also affected by fishery residues, many of which have severe pollution impacts on marine ecosystems. In addition, Taiwan's coastal waste discharge has also caused great pollution and impact on marine ecosystems.
You:Alternatively, consider this series of Q&A:
You: Is Japan's air pollution serious?
Bot:
Air pollution is a serious problem in Japan. According to the pollution chart published by the World Health Organization (WHO) in 2018, Japan is one of the best places in the world in terms of air pollution index, and the total index is higher than the global average. While the Japanese government has made efforts to combat air pollution, there is still considerable room for improvement.
You: What about Taiwan?
Bot:
Air pollution in Taiwan is also serious. According to the World Health Organization's data, Taiwan's air pollution index is higher than the global average, and it is also one of the places where the air pollution index is higher than the global average. Despite the efforts of the Taiwanese government, there is still much room for improvement in the fight against air pollution.
You:In the response related to Taiwan, it adds the word “also” to explicitly show that it understands this is a follow-up to the previous question about Japan.
To improve the effectiveness, you can include the entire history of the conversation, rather than just the previous Q&A as shown in the above examples. If you’re concerned about exceeding the token limit due to a long conversation history, you can use the method mentioned earlier to calculate the token count. When the count is too high, you can ask OpenAI to provide a summary of the conversation history, using the summary as the conversation input. This can significantly reduce the data size.

ChatGPT API Python
However, if you want to use Python, there are basically two popular methods.
- Using the
requestsmodule to connect to the API - Directly using the OpenAI package
Using the requests module to connect to the API, or Directly using the OpenAI package. Below is the code for the first method:
Using the requests module to connect to the API (text completion)
import requests
def call_chatgpt_api(api_key, prompt):
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
else:
raise Exception("Request failed with status code: " + str(response.status_code))
# Set your API key and prompt
api_key = "YOUR_API_KEY"
prompt = "Hello, can you help me with writing a creative story?"
# Call the ChatGPT API
response = call_chatgpt_api(api_key, prompt)
# Print the generated text
print(response)Remember to replace "YOUR_API_KEY" with your actual API key. This code demonstrates the first method using the requests module to make an API call to ChatGPT and retrieve the generated response.
The prompt is the string that you input to the model, while max_tokens sets the maximum length of the response generated by the model. The temperature parameter is related to the randomness of the model’s output, and model refers to the specific model you want to use.
model price
One important aspect to consider is the model parameter, as different models have varying parameters, capabilities, and costs. The pricing and size of each model can be referenced on OpenAI’s pricing page.
Some people may have concerns about using their credit card and the possibility of it being locked. In general, every new account comes with a free credit of $18, which can be tracked from the “Manage Account” section in the personal account menu.
chat completion and Whisper API
Also using the requests module to connect to the API, or Directly using the OpenAI package.
# 1. Using the request module to connect to the API
api_key = [Enter your API key]
prompt = [Text you want to provide]
response = requests.post(
‘https://api.openai.com/v1/chat/completions’,
headers = {
‘Content-Type’: ‘application/json’,
‘Authorization’: f’Bearer {api_key}’
},
json = {
‘model’: ‘gpt-3.5-turbo’, # Make sure to use a model suitable for chat
‘messages’ : [{“role”: “user”, “content”: prompt}]
})
#Using json parsing
json = response.json()
print(json)
The above code requires some attention to the messages parameter. The message is actually the chat history that you provide to ChatGPT, and its format is as follows.
messages=[
{“role”: “system”, “content”: “You are a helpful assistant.”},
{“role”: “user”, “content”: “Who won the world series in 2020?”},
{“role”: “assistant”, “content”: “The Los Angeles Dodgers won the World Series in 2020.”},
{“role”: “user”, “content”: “Where was it played?”}
]
There are three roles: “system,” “user,” and “assistant.” When starting to use chatGPT, it is common to provide a system message to instruct chatGPT on how to behave. However, with the gpt-3.5-turbo model, the system message may not have a significant impact. If you want to guide the behavior of chatGPT, it is better to use prompt engineering (which will be explained later).
“user”: This role is used for inputting the user’s messages or questions.
“assistant”: This role represents the previous responses from ChatGPT in earlier rounds of conversation. Therefore, for multi-round chatGPT, you need to keep track of the conversation history and input it repeatedly (there might be better methods for this).
In conclusion, besides the mentioned approaches, I believe the most noteworthy aspect is that gpt-3.5-turbo is 10 times cheaper than text-davinci-003 while producing similar results. This means that all GPT-based methods have become much more cost-effective. I highly recommend engineers who want to incorporate ChatGPT into their products to give it a try.


OpenAI API
ChatGPT is one application built upon the GPT model. In fact, OpenAI offers various models, and this article specifically focuses on introducing the GPT API. For information about other OpenAI APIs, their applications, and how to choose between them, please refer to this article.
👉OpenAI API tutorial model : GPT4,GPT3.5,DALL·E,Whisper,Embeddings,Moderation,GPT3,Codex……
🙋♂️ How to use ChatGPT ? Latest Information
🔖 upgrade、app、api、plus、alternative、login、download、sign up、website、stock