

ChatGPT is an application based on the GPT model. In fact, OpenAI offers not only GPT models but also various other models. This chapter provides a categorized summary of these models and offers guidance on how to choose among them.
💪 ChatGPT API Python,Github,Node.js tutorial : detailed coding procedure
🙋♂️ How to use ChatGPT ? Latest Information
🔖 upgrade、app、api、plus、alternative、login、download、sign up、website、stock
What is OpenAI
OpenAI is an artificial intelligence research laboratory and company that focuses on developing and promoting safe and beneficial AI. It was founded in December 2015 with the goal of advancing artificial general intelligence (AGI), which refers to highly autonomous systems that outperform humans in most economically valuable work.
OpenAI conducts research in various fields of AI and develops state-of-the-art models and technologies. They have released several prominent AI models, including GPT (Generative Pre-trained Transformer) models like GPT-3, which have demonstrated remarkable capabilities in natural language processing and text generation.

In addition to research and model development, OpenAI also offers APIs (Application Programming Interfaces) that allow developers to access and utilize their AI models for various applications and tasks. These APIs enable developers to integrate powerful language models into their own software systems and create innovative applications.
OpenAI is committed to promoting the safe and ethical development of AI and actively participates in AI policy and governance discussions. They emphasize the responsible use of AI technology and strive to ensure that AI benefits all of humanity.
OpenAI API models
| OpenAI model | Description |
| GPT-4 (limited access) | A set of models built upon GPT-3.5 that can understand and generate natural language or code. |
| GPT-3.5 | A set of models built upon GPT-3 that can understand and generate natural language or code. |
| DALL·E (public beta) | A model capable of generating and editing images based on natural language prompts. |
| Whisper (public beta) | A model that converts audio into text. |
| Embeddings | A set of models that convert text into numerical representations. |
| Moderation | A fine-tuned model for detecting sensitive or unsafe text. |
| GPT-3 | A set of models capable of understanding and generating natural language. |
| Codex (deprecated) | A set of models that can understand and generate code, including converting natural language to code. |

GPT4_openai api
A large multimodal model with higher accuracy than any previous models, capable of solving complex problems. It currently supports receiving text inputs and generating text outputs, with future support for image inputs. It possesses a broader range of general knowledge and advanced reasoning capabilities. Similar to gpt-3.5-turbo, GPT-4 is optimized for chat-based applications but is also applicable to traditional completion tasks.
| Model | Description | Max Tokens | Training Data |
| gpt-4 | More powerful than any GPT-3.5 model, capable of handling more complex tasks, and optimized for chat-based applications. It will be updated with iterations of our latest models. | 8,192 tokens | September 2021 |
| gpt-4-0314 | A snapshot of GPT-4 released on March 14, 2023. Unlike gpt-4, this variant will not receive updates and will only be supported for three months until June 14, 2023. | 8,192 tokens | September 2021 |
| gpt-4-32k | Functionally similar to the base GPT-4 model but with a context length four times that of GPT-4. It will be updated with iterations of our latest models. | 32,768 tokens | September 2021 |
| gpt-4-32k-0314 | A snapshot of GPT-4-32k taken on March 14, 2023. Unlike gpt-4-32k, this variant will not receive updates and will only be supported for three months until June 14, 2023. | 32,768 tokens | September 2021 |
For many basic transactions, the differences between the GPT-4 and GPT-3.5 models do not show up. However, in more complex inference scenarios, GPT-4 outperforms any previous model.
GPT3.5_openai api
The GPT-3.5 model is capable of understanding and generating natural language or code. The most powerful and cost-effective variant in the GPT-3.5 series is GPT-3.5-turbo, which is optimized for chat-based applications but also suitable for traditional completion tasks.
| Model | Description | Max Tokens | Training Data |
| gpt-3.5-turbo | The most powerful GPT-3.5 model, optimized for chat-based applications, at 1/10th the cost of text-davinci-003. It will be updated with iterations of our latest models. | 4,096 tokens | September 2021 |
| gpt-3.5-turbo-0301 | A snapshot of gpt-3.5-turbo taken on March 1, 2023. Unlike gpt-3.5-turbo, this variant will not receive updates and will only be supported for three months until June 1, 2023. | 4,096 tokens | September 2021 |
| text-davinci-003 | Compared to curie, babbage, or ada models, it can complete any language task with better quality, longer output, and consistent instruction following. It also supports text completion. | 4,097 tokens | June 2021 |
| text-davinci-002 | Similar to text-davinci-003 in functionality, but trained using supervised fine-tuning instead of reinforcement learning. | 4,097 tokens | June 2021 |
| code-davinci-002 | Optimized for code completion tasks. | 8,001 tokens | June 2021 |
It is recommended to use gpt-3.5-turbo instead of other GPT-3.5 models due to its lower cost.
GPT3_openai api
The GPT-3 model is capable of understanding and generating natural language. These models have been replaced by the more powerful GPT-3.5 models. However, the original GPT-3 base models (davinci, curie, ada, and babbage) are currently the only ones that can be fine-tuned.
| Model | Description | Max Tokens | Training Data |
| text-curie-001 | More powerful and faster than Davinci, with lower cost. | 2,049 tokens | October 2019 |
| text-babbage-001 | Capable of completing simple tasks, very fast, and with lower cost. | 2,049 tokens | October 2019 |
| text-ada-001 | Capable of completing very simple tasks, typically the fastest and lowest-cost variant in the GPT-3 series. | 2,049 tokens | October 2019 |
| davinci | The most powerful GPT-3 model. Capable of completing any task that other variants can handle, usually with higher quality. | 2,049 tokens | October 2019 |
| curie | Powerful, but faster and lower-cost compared to Davinci. | 2,049 tokens | October 2019 |
| babbage | Capable of completing simple tasks, very fast, and with lower cost. | 2,049 tokens | October 2019 |
| ada | Capable of completing very simple tasks, typically the fastest and lowest-cost variant in the GPT-3 series. | 2,049 tokens | October 2019 |
DALL·E_openai api
DALL·E is capable of generating realistic images and artwork based on natural language descriptions. It currently supports creating images of specific sizes, modifying existing images, or creating variations of user-provided images based on given prompts.
Whisper_openai api
Whisper is a general-purpose speech recognition model. Trained on a large audio dataset, it is also a multitask model capable of performing multilingual speech recognition and speech translation. Currently, there is no distinction between the open-source version of Whisper and the version provided through the API. However, using Whisper through the API offers an optimized inference process, making it much faster than running it through other means.
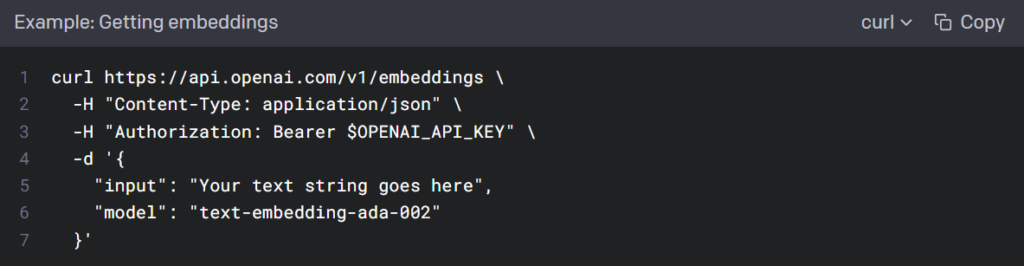
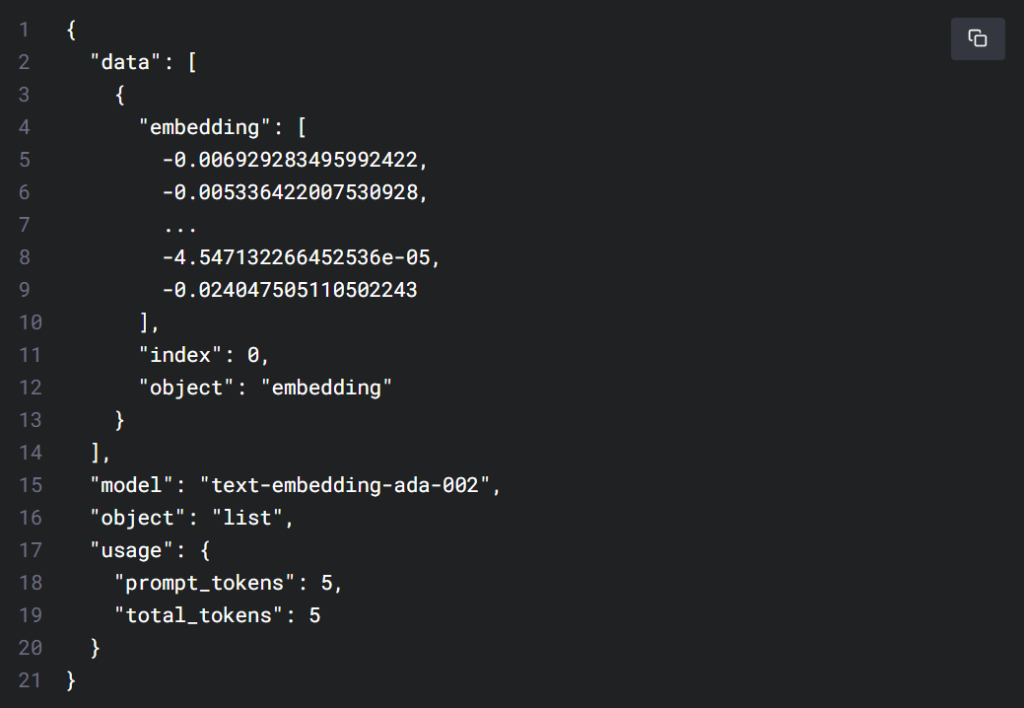
Embeddings_openai api
Embeddings are numerical representations of text that can be used to measure the correlation between two pieces of text. The second-generation embedding model, text-embedding-ada-002, aims to replace the previous 16 first-generation embedding models at a lower cost. Embeddings are highly useful for tasks such as search, clustering, recommendation, anomaly detection, and classification.
By mapping each word or character in the text to a vector in a mathematical space, Embeddings transforms text data into a series of numbers. These numbers can be used by computers for various text processing tasks, such as sentiment analysis, topic classification, and text generation. Similar to how humans associate words with meanings while learning language, the Embeddings model learns to extract semantic information from text data and map words or characters to positions in the vector space. This allows computers to understand the semantic relationships in text data by comparing the distances and similarities between these vectors, enabling various text processing tasks.
Moderation_openai api
The Moderation model is designed to check whether content complies with OpenAI’s usage policies. The model provides classification capabilities to identify content in the following categories: hate, hate/threat, self-harm, sexual, sexual/minor, violence, and violence/image.
The model accepts inputs of any size, which are automatically broken down to fit the specific context window of the model.
| Model | Description |
| text-moderation-latest | The most capable moderation model. It offers slightly higher accuracy compared to the stable model. |
| text-moderation-stable | Almost as effective as the latest model, but slightly older. |
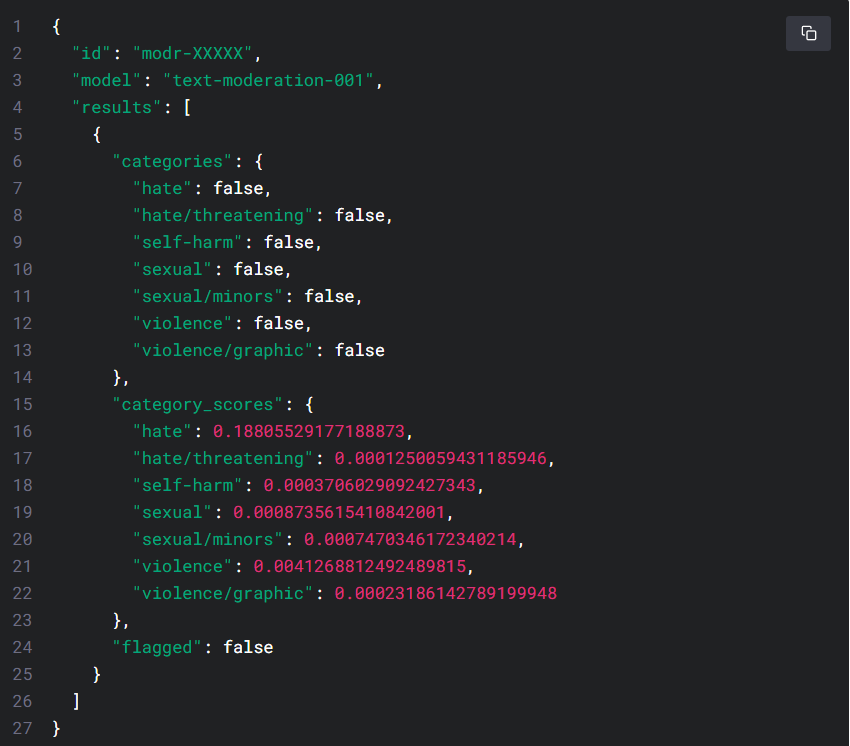
flagged: Set totrueif the model classifies the content as violating OpenAI’s usage policies,falseotherwise.categories: Contains a dictionary of per-category binary usage policies violation flags. For each category, the value istrueif the model flags the corresponding category as violated,falseotherwise.category_scores: Contains a dictionary of per-category raw scores output by the model, denoting the model’s confidence that the input violates the OpenAI’s policy for the category. The value is between 0 and 1, where higher values denote higher confidence. The scores should not be interpreted as probabilities.
Codex_openai api
The Codex models have now been deprecated. They are descendants of the GPT-3 model and are capable of understanding and generating code. The training data includes billions of lines of public code from natural language and GitHub. They are proficient in Python and have expertise in several languages, including JavaScript, Go, Perl, PHP, Ruby, Swift, TypeScript, SQL, and even Shell. The following Codex models are now deprecated:
| Model | Description | Max Tokens | Training Data |
| code-davinci-002 | The most powerful Codex model. Particularly adept at translating natural language into code. In addition to code completion, it also supports code insertion. | 8001 tokens | June 2021 |
| code-davinci-001 | Early version of code-davinci-002. | 8001 tokens | June 2021 |
| code-cushman-002 | Almost as powerful as Davinci Codex but with slightly faster speed. This speed advantage may make it more suitable for real-time applications. | 2048 tokens | — |
| code-cushman-001 | Early version of code-cushman-002. | 2048 tokens | — |
While Codex has been deprecated, OpenAI recommends that all users switch to GPT-3.5 Turbo, which can both fulfill coding tasks and provide flexible natural language capabilities.
Why was Codex deprecated?
Codex is a code autocompletion tool based on the GPT model, introduced by GitHub. It generates the next code snippet based on the context of the code snippet, helping developers improve their programming efficiency. However, GitHub announced in August 2021 that they would stop supporting Codex, and it was officially deprecated in March 2023.
The main reason for GitHub’s decision to stop supporting Codex is related to the usage license of GPT-3. GPT-3 was developed and owned by OpenAI and was licensed exclusively to certain partners, including GitHub. However, in June 2021, OpenAI announced that they would no longer grant licenses for GPT-3 to new partners. This means that even if GitHub wanted to continue using Codex, they could no longer obtain the licensing rights for GPT-3.
Additionally, some limitations of Codex itself may have contributed to its deprecation. For example, it can only handle a limited number of programming languages and may not support all programming languages and libraries. Furthermore, due to the complexity of code syntax and semantics, the code generated by Codex may not adhere to coding conventions and best practices, potentially leading to security issues.
In summary, the deprecation of Codex is likely due to licensing issues and its own limitations. Although GitHub has stopped supporting Codex, its development ideas and technologies still hold value as a reference and may see further advancements in future code autocompletion tools.
OpenAI Model and API Endpoint Compatibility
This section covers the compatibility between different versions or types of OpenAI models and API endpoints. As OpenAI continuously updates and improves its models and API, there may be multiple versions or types of models available. It helps you choose the appropriate model version to pair with an API endpoint to ensure compatibility and proper functionality.
You can refer to the table below to determine the specific API to use:
| API | Model |
| /v1/chat/completions | gpt-4, gpt-4-0314, gpt-4-32k, gpt-4-32k-0314, gpt-3.5-turbo, gpt-3.5-turbo-0301 |
| /v1/completions | text-davinci-003, text-davinci-002, text-curie-001, text-babbage-001, text-ada-001, davinci, curie, babbage, ada |
| /v1/edits | text-davinci-edit-001, code-davinci-edit-001 |
| /v1/audio/transcriptions | whisper-1 |
| /v1/audio/translations | whisper-1 |
| /v1/fine-tunes | davinci, curie, babbage, ada |
| /v1/embeddings | text-embedding-ada-002, text-search-ada-doc-001 |
| /v1/moderations | text-moderation-stable, text-moderation-latest |
OpenAI API application
Text Completion
The completion interface is used to generate or manipulate text. It provides a simple yet powerful interface for any model. You input some text as a prompt, and the model generates a text completion, attempting to match any context or pattern you give it.
For example, if you pass the following prompt to the API:
Write a slogan for an ice cream shop.
It will return the completed information:
Every spoon brings you a smile!
The above is just a simple example, in reality, the model can do anything from generating original stories to performing complex text analysis. Because it can do anything, you must explicitly describe what you want. Instead of telling, showing it how to respond is often the key to a good prompt.
There are three basic guidelines for creating prompts:
- Describe and show: Be explicit about what you want by explaining, providing examples, or a combination of both. If you want the model to rank a list of items alphabetically or classify paragraphs based on sentiment, show it what you want.
- Provide high-quality data: If you’re trying to build a classifier or make the model follow a pattern, make sure you have enough examples. Proofread your examples—while the model is usually smart enough to overlook basic spelling errors and still provide a response, it may also interpret them as intentional, which can affect your response.
- Check your settings: The‘
temperature‘ and ‘top_p‘settings control the model’s determinism when generating responses. If you want it to give an answer with only one correct response, you should set them lower. If you’re looking for more diverse responses, you should set them higher. The first mistake people make with these settings is thinking they control “smartness” or “creativity.”
Chat Completion
With OpenAI’s Chat API, you can use the gpt-3.5-turbo model and the gpt-4 model to build your own applications and achieve functionalities similar to the following:
- Writing an email.
- Writing Python code.
- Answering questions about a set of documents.
- Creating a conversational agent.
- Providing a natural language interface for your software.
- Tutoring in a range of subjects.
- Language translation.
The chat models take a series of messages as input and return generated messages from the model as output.
Token Management
Language models read text in chunks called tokens. In English, a token can be a character or a word (e.g., “a” or “apple”), and in some languages, tokens can be shorter than a single character or longer than a single word.
For example, the string “ChatGPT is great!” is encoded into 6 tokens: [“Chat”, “G”, “PT”, ” is”, ” great”, “!”].
When processing Chinese text, GPT models typically use a character-level tokenization approach, treating each Chinese character as a separate token. This is because Chinese words do not have explicit separators like spaces, so treating words as tokens directly could lead to inaccurate word segmentation and affect model performance.
The total number of tokens in your API call affects:
- The cost of your API call, as you are billed per token.
- The time required for the API call, as more tokens require more processing time.
- Whether your API call works, as the total token count must be below the model’s maximum limit.
Both the input and output tokens count towards these numbers. For example, if your API call uses 10 tokens for the input and you receive an output of 20 tokens, you will be billed for 30 tokens.
To check how many tokens were used in an API call, you can inspect the ‘usage‘ field in the API response (e.g., ‘response['usage']['total_tokens']‘).
To count tokens in a text string without making an API call, you can use OpenAI’s ‘tiktoken‘ Python library. Sample code for counting tokens using‘ tiktoken‘ can be found in the OpenAI Cookbook’s guide on how to count tokens.
How to Guide Chat Models
If the model is not providing the desired response, feel free to iterate and try potential improvements. Here are some methods you can use:
- Make your prompts more explicit: Provide clearer instructions in your prompts to guide the model towards the desired answer.
- Specify the format you want the answer in: If you have a specific format or structure in mind for the answer, make sure to communicate that to the model.
- Walk the model through the steps: Guide the model through the logical steps or thought process, or ask it to consider both sides of an argument before settling on an answer.
For more details, you can refer to the OpenAI Cookbook’s guide on techniques to improve reliability.
Chat vs Completions
Due to the comparable performance of gpt-3.5-turbo to text-davinci-003, but at only 10% of the price per token, we recommend using gpt-3.5-turbo in most use cases.
Image generation
Use the DALL·E model to generate or manipulate images. The Image API provides three methods for interacting with images:
- Create images from scratch based on textual descriptions.
- Make edits to existing images based on new textual prompts.
- Generate variations of existing images.
You can use the DALL·E preview app for online previews.
learn more :
🙋♂️ How to use ChatGPT ? Latest Information
🔖 upgrade、app、api、plus、alternative、login、download、sign up、website、stock